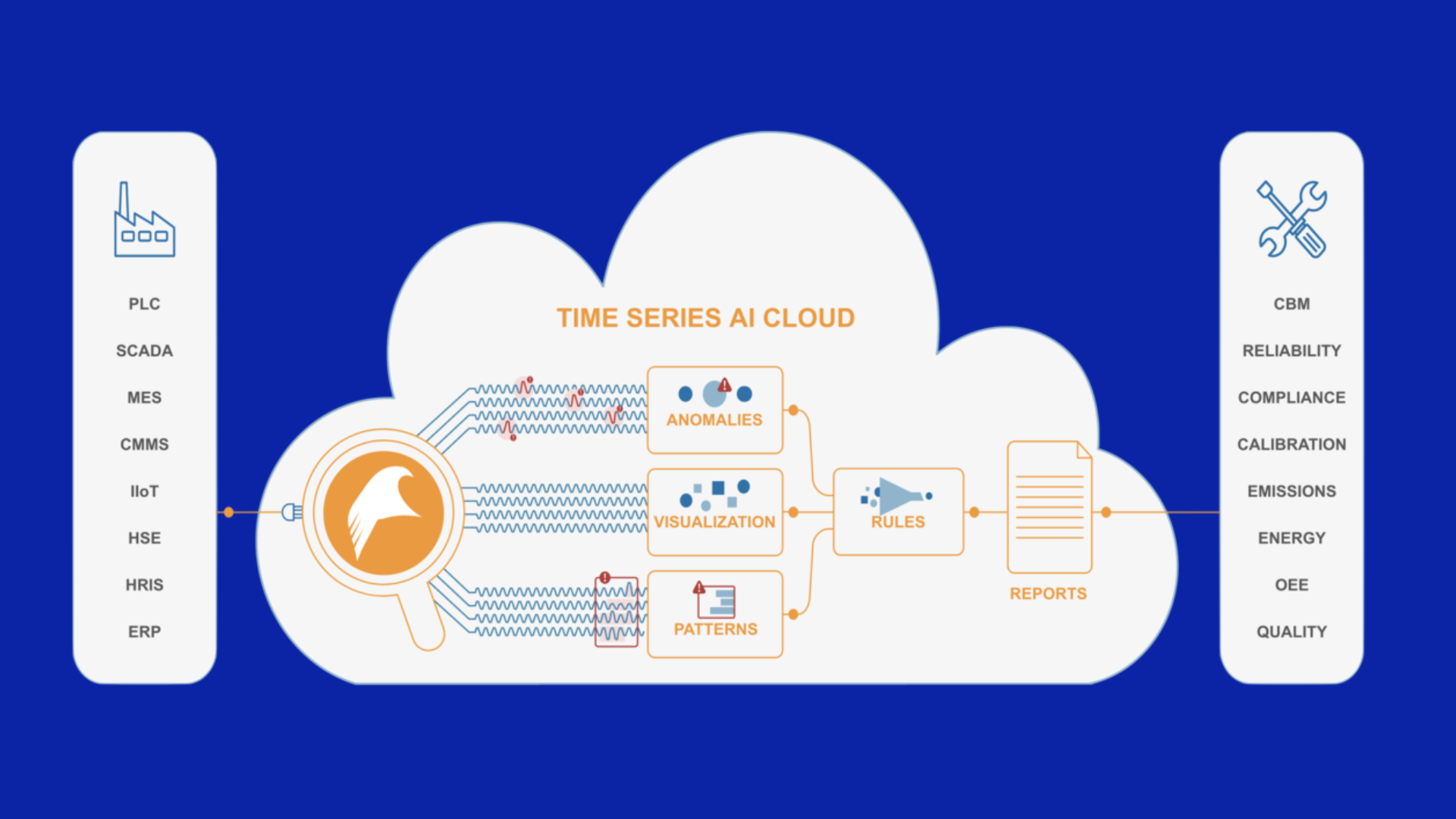
Limitations and Hazards of AI in industrial operations

Key takeaways:
- While AI isn’t universally applicable, it is particularly suited to the kind of multivariate, repetitive pattern recognition involved in industrial operations.
- In the manufacturing world, the goal of AI is not to replace human thinking, but rather to assist operational decision-making by unearthing meaningful information from data.
- There is enough commonality in most industrial systems for AI to potentially become a one-size-fits-all solution.
- AI implementation hazards such as labelling inconsistency, use-case specificity, and ethical issues are not endemic to the technology and can be overcome with planning.
Industry pundits almost universally hail Artificial Intelligence as a technology that is the next game changer, poised to disrupt a vast number of businesses – from banking to manufacturing, healthcare to logistics, and everything in between. However, with this unbridled enthusiasm for AI, comes a whole set of misconceptions and myths, along with some legitimate concerns about whether such industry-wide exuberance around this technology is somewhat misplaced. And no, we aren’t talking about fears of a Skynet-like machine uprising, but rather realistic concerns about the supposed universal applicability of AI, and its gung-ho positioning as the silver bullet to solve all manner of problems.
AI skeptics often oppose the technology by harping on its ineptness at emulating human intuition, its inability to “think” laterally and make out-of-the-box decisions, or its inability to recognize attempts to deliberately subvert systems. For many of the applications that AI is being widely considered for, these counter-arguments are fairly valid. However, are these limitations of AI really applicable to industrial operations? We believe they are not. Let’s find out why.

Limitations of AI?
True multitasking and no fatigue
Humans are quite adept at tasks such as identifying the odd one out in a set of nearly alike items or quantities. We all remember doing such puzzles in our early childhood. Often, the odd one out is an object that is similar or belongs to the set in all attributes except one. This is a learned ability that comes from the experience of approaching a problem from different angles. However, even ordinary individuals can spot such out-of-place items quite easily, meaning one doesn’t have to be extraordinarily smart or highly educated to be good at this. The problem arises when this task has to be performed repeatedly. This is where AI wins hands down. While constant repetition quickly overwhelms human operators, AI does not get tired. Also, human cognitive abilities get overwhelmed when bombarded with too many stimuli. For example, human ability to deal with concurrent problems is lower than AI’s; we are more ok dealing with problems that occur consecutively. Humans are also not good at synthesizing and understanding the world from multiple sources of information.
But, in the world of manufacturing, data from process parameters is being produced and collected all the time. Data denoting raw material characteristics, data from inspection tools like vibration or current sensors, data from oil analysis, ultrasound testing, etc, is constantly streaming in at once, in real time. Synthesizing all of this into a common understanding can be very challenging even for the smartest person, because there’s just too many different points of view that have to be consolidated. AI, unsurprisingly, is much better at this than any of us.
AI cannot think for itself, but it does not need to; in fact, it shouldn’t
While it is true machines cannot easily alter their responses to changing environments or that change in input needs retraining of AI, it is not the goal of AI to replace the thinking ability of a human being. Thinking is still primarily done by humans and not by computers, and this is true even in manufacturing. Contrary to the popular misconception, AI isn’t waiting in the wings to take over. The manufacturing leadership will continue making the important calls related to labor, new markets exploration, or product development. Ultimately, these are not decisions for AI to make on its own accord. In the manufacturing world AI will continue to be used to assist those decisions by analyzing patterns and unearthing meaningful information from data.

AI may not be one-size-fits-all yet, but history shows it will evolve to get there
The general belief, not just in lay circles, but even with industry insiders, is that AI can never transition to be a one-size-fits-all solution. Prima facie, considering the wide disparity in the nature of the problems AI is expected to solve, this doesn’t feel farfetched. Surely, the kind of AI models used to determine dynamic pricing for effective marketing will be different from the models that will predict equipment failure in steel manufacturing. However, a quick look in the rear view mirror tells us that historically technologies have the tendency to morph into not just “off label” use, but eventually even mature towards universal applicability.
When the telegraph first came about, almost 200 years ago, it would’ve been hard to imagine expanding its scope from mere communications, to say the ability to instantly transfer money across vast distances. In more recent times, databases were built ground up for each individual use-case and application. Interoperability was unheard of in the early days of database management systems, until relational databases came along, with the ability to define the schema for every database. Suddenly, this opened up the possibility of a vast number of applications for database technology. Similarly, statistical process control originated in the nuclear power-generation industry, and was brought over into chemicals, pulping paper, pharmaceuticals and discrete manufacturing. Statistical process control was just a tool, which eventually evolved, and could then be applied beyond nuclear engineering or nuclear power generation into other fields. It is not hard to imagine a similar tech disruption taking place with AI as well, possibly quite soon.
For now, we have to acknowledge that AI won’t find applicability across both stochastic and deterministic fields. Things like marketing and industrial manufacturing are vastly different. Marketing is directed at human behavior, which is at times unpredictable, whereas industrial AI is directed at physical characteristics – processes that are governed by natural laws.
Within such domains there is definitely scope for a one-size-fits-all solution. For most of these physical processes, as long as there is sufficient instrumentation, and AI is able to identify what behavior is important, we will be able to extract meaningful inferences both on the input side or on the output side.
Over time, this approach of understanding behavior patterns can become generally applicable, but it requires, at its core, the ability to discern physical behaviors. And there are certain characteristics of common physical behaviors in manufacturing environments. For instance, manufacturing environments are actually producing something. Since they are producing output, they are also producing vast amounts of parametric data related to vibration, temperature, flux and other process parameters. This data is so similar that differences are not easily noticeable to people. But to Falkonry Time Series AI it is a veritable sea of trends, patterns and statistical correlations – a window into the inner workings of machines and processes, ripe for surfacing meaningful insights.
Hazards of AI
Unlike the “limitations” discussed above, a hazard – in the way we’ll define it for the purpose of this article – is an obstacle or a potential danger that makes you deviate from the path when applying AI for industrial operations. It isn’t an inherent flaw endemic to the technology itself, but more of an impediment to successful implementation. Hence, it can be overcome by planning.
Ethics: An AI system will be as good as the people that train it
One of the points often brought up about AI is that since it cannot figure out right from wrong, there can be undesirable outcomes in matters related to security, privacy or societal scenarios. While these do not directly apply to the industrial or manufacturing context, they do highlight a concept related to training AI. As we’ve said before, humans are better at thinking and computers are better at doing (even if the tasks being performed are intelligent tasks). Hence, respect for human knowledge cannot be underestimated when applying AI in the industrial world. The intelligence of an AI system will only get better through the active participation and cooperation of humans who want to delegate certain tasks to machines and computers. Therefore, subject matter experts will always play a significant role in the shaping of AI. The corollary is that the individual biases of the humans training the AI will creep into it. This brings us to a potential hazard – that of labelling, since labelling is one of the mechanisms by which AI learns and captures the tacit knowledge of humans, especially in the case of supervised AI.
Labelling: Best practices can limit errors
Labeling is the metadata whose quality determines, in many ways, the quality of the AI itself. AI can be as good in its task of classification as the effort put in by the SME to label the various conditions. If the labeling and the capturing of tacit knowledge is not done properly, then AI will be limited in its capabilities. However, to overcome this hazard, there are certain data integrity best practices or processes that can be implemented to ensure consistency of labelling.
Use-case specificity: Broad application should be the goal
In the industrial world, we can get into the trap of developing AI applications that are very specific to use cases. Bespoke development projects like these are inherently difficult to scale. Secondly, while applying AI, a common practice is to apply the AI to one use case and prove the value it is generating, and only then subsequently apply it to other areas when the value in the first use case is firmly established. This can obviously hamper adoption. Our experience with AI, and particularly when it comes to scaling, reveals that adequate benefits from AI accrue not from depth of application, but from broad application across a large number of applications. This kind of approach garners benefits of economies of scale and the AI model is also able to learn and deliver quickly.