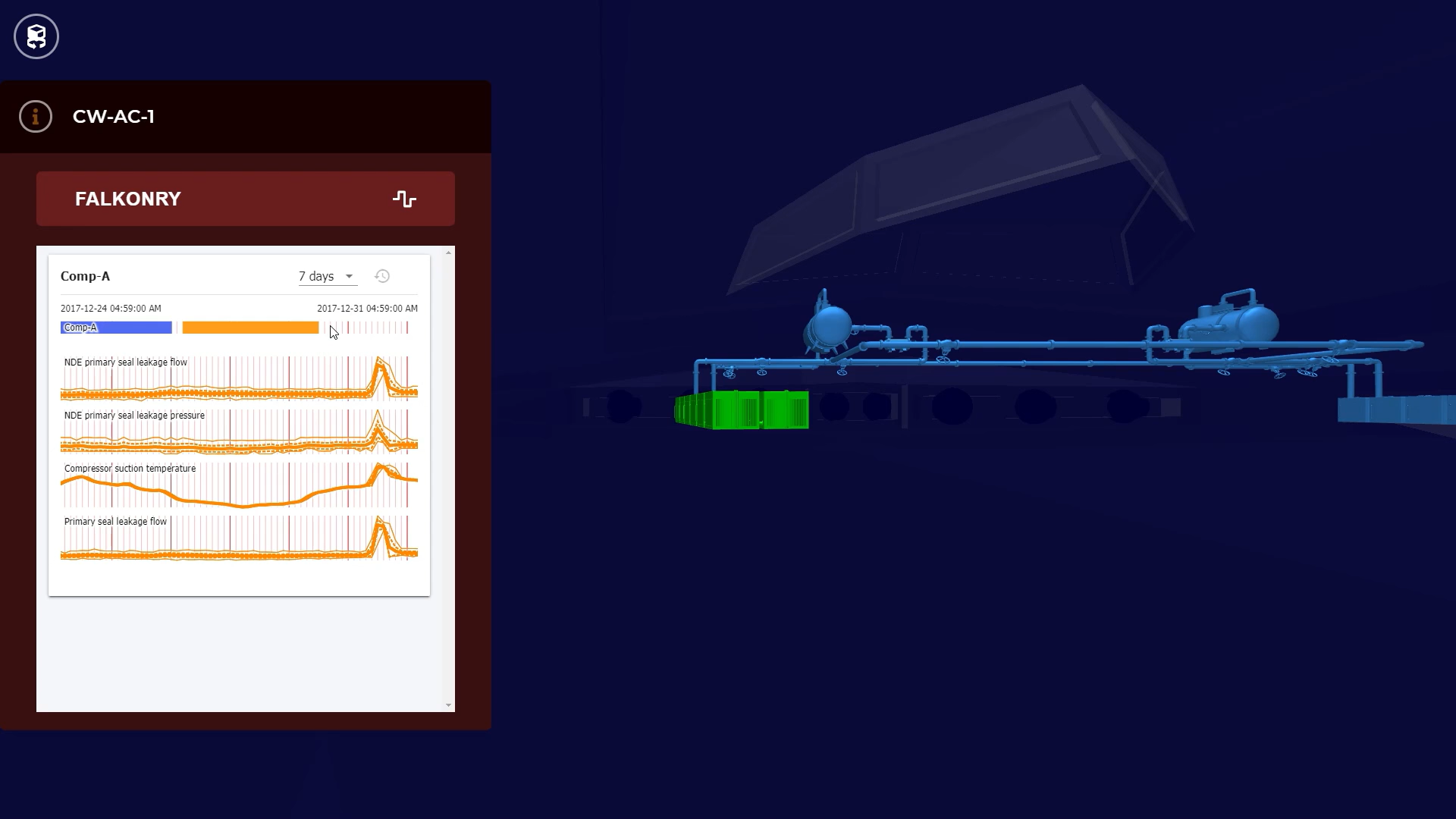
Designing an intelligent system for high reliability production line

Key takeaways:
- Combined analysis of process and sensor data is extremely valuable for predictive maintenance
- Fears of perfection, narrow focus, and regulatory compliance are major hurdles faced in improving reliability through predictive analytics

Manufacturing processes today are under continuous pressure to improve yield, throughput and eventually the ROI. This brings reliability and maintenance in sharp focus to ensure minimum breakdowns and reduce unplanned downtime. To maximize efficiency and operational excellence, M&R teams are increasingly turning to Industry 4.0 technologies and advanced approaches to reliability.
In this candid talk, Nikunj Mehta, Founder and CEO of Falkonry, an innovation leader in time series AI, talks about the progress reliability techniques have made and how operations teams are using AI.
Q: What is exciting in the world of reliability and maintenance?
Nikunj:
Reliability Centered Maintenance (RCM) has been around for a long time but, due to the historical difficulty and cost of getting real time data, has been focused on FMECA and statistical analyses to determine which equipment to service and when. Now, sensors, data transfer, data storage and advanced analytics are becoming very cost effective. This enables more powerful RCM approaches like Condition Based Maintenance (CBM) and Predictive Maintenance (PdM) to be feasible in more and more applications.
To understand what’s new, let’s first look at the different approaches RCM utilizes to defining maintenance plans:
- Scheduled a.k.a Preventative Maintenance (PM) cycles – occur on a fixed schedule
- Condition based – occur as needed based on measurements
- Predictive – use measurements and analytic models to estimate how much time is left before service is needed
All of these are approaches to non-reactive (break-fix) maintenance. Preventative Maintenance is simple to set up and conservative in preventing failures but drains resources with more than the minimum necessary maintenance cycles. This results in lost productivity, higher consumables cost and more manpower required.
The next approach in the progression is CBM. This can range from simple rules to complex rules and from manual data collection e.g., with analysis sensors and inspection tools to automated periodic collection with screening sensors and low frequency sampling.
CBM relies on specialized analysis tools for specific types of inspection. The availability of low cost sensors and wireless connectivity like LPWan, 3G/4G Cellular, 5G and WiFi v6 make retrofitting easier than ever before. CBM algorithms have also made progress. For example, it has moved from being able to work with only simple, univariate rules to more complex condition detection, using multivariate analysis across a wide range of sensors. SaaS puts a more accessible and always available delivery mechanism for exploiting the sensing hardware than before.
Taking CBM to the next level is Predictive Maintenance. Here, we look for better precursors and use those precursors in estimating time to failure with more complex modeling. This is the next frontier and is enabled by the same technologies and techniques which make CBM such an exciting space. PdM is also able to look at larger volumes of data including through higher bandwidth sensing and by using process parameters. As a result, it finds earlier signs, more unknown unknowns, better explanation, and better tolerance to noise and process variations.
Being able to say when maintenance is needed is powerful for scheduling both people and production but this is a difficult thing to do well – it’s still at the cutting edge of maintenance strategy.
Q. Where do organizations get stuck in their predictive maintenance approach?
Nikunj:
In one word: “perfection!” Taking the approach of not starting anything unless it works perfectly stalls and eventually leads to abandonment of many good and valuable projects.
For example, an organization wants to implement predictive maintenance strategies but they will implement it only if it can predict every single failure mode – even the most complex ones. Now that’s a very high bar to set at the onset of such a project.
Instead, they should focus on finding a single, common failure mode in one equipment in order to see real value from the strategy. This does 3 things:
- It solves a real problem
- It engages stakeholders to find more such work
- It lets the organization start learning how to do this. It’s not easy, and experience shows there are many systemic issues, such as people, data quality and processes, that will hinder progress. Learning about them this way, on a smaller project, provides great returns at lower risk once the decision is made to scale up.
A key challenge is answering “what is the right problem?” We recommend taking a use case based approach. Review possible applications with a range of potential participants and see which ones stir a “I have that problem too” moment. The goal is to find a couple of things that resonate – that move us one step closer to showing the art of the possible. The goal is not to find the “perfect” problem which will achieve a 10x ROI in 1 year.
Let’s also talk about mindset. Decision makers need to adopt a monitoring mindset rather than a root-cause analysis mindset. Put another way, approaching with the stance that having and acting on imperfect knowledge now can be more important than having perfect knowledge later. Achieving awareness of what’s going in the line, at scale, with good-enough data from commodity sensors, driven by analysis tools that your existing operations team can actually use, without the help of data scientists or highly credentialed reliability experts, can go a long way to achieving value and achieving it quickly.
Fear of not being compliant with regulations is another hurdle organizations face. A paper on innovations in pharma manufacturing makes an important distinction between verifying and assisting in verification. Verification is a 3 stage process with a high level of analysis and testing required to get approval. Yes, it is difficult to change after getting that regulatory approval. However, many of the CBM and PdM techniques can be used to supplement verification rather than replace it. For example: A continuous verification process may have established strict control limits based on months of characterization. Predicting when maintenance is necessary doesn’t replace that verification process. Rather it assists the process to be more effective by warning when the equipment is likely to start experiencing failures as defined by the verification process’ control limits. With this assistance, the maintenance team can take proactive steps to avoid ever failing in the first place. Assistance like this does not require a costly requalification..
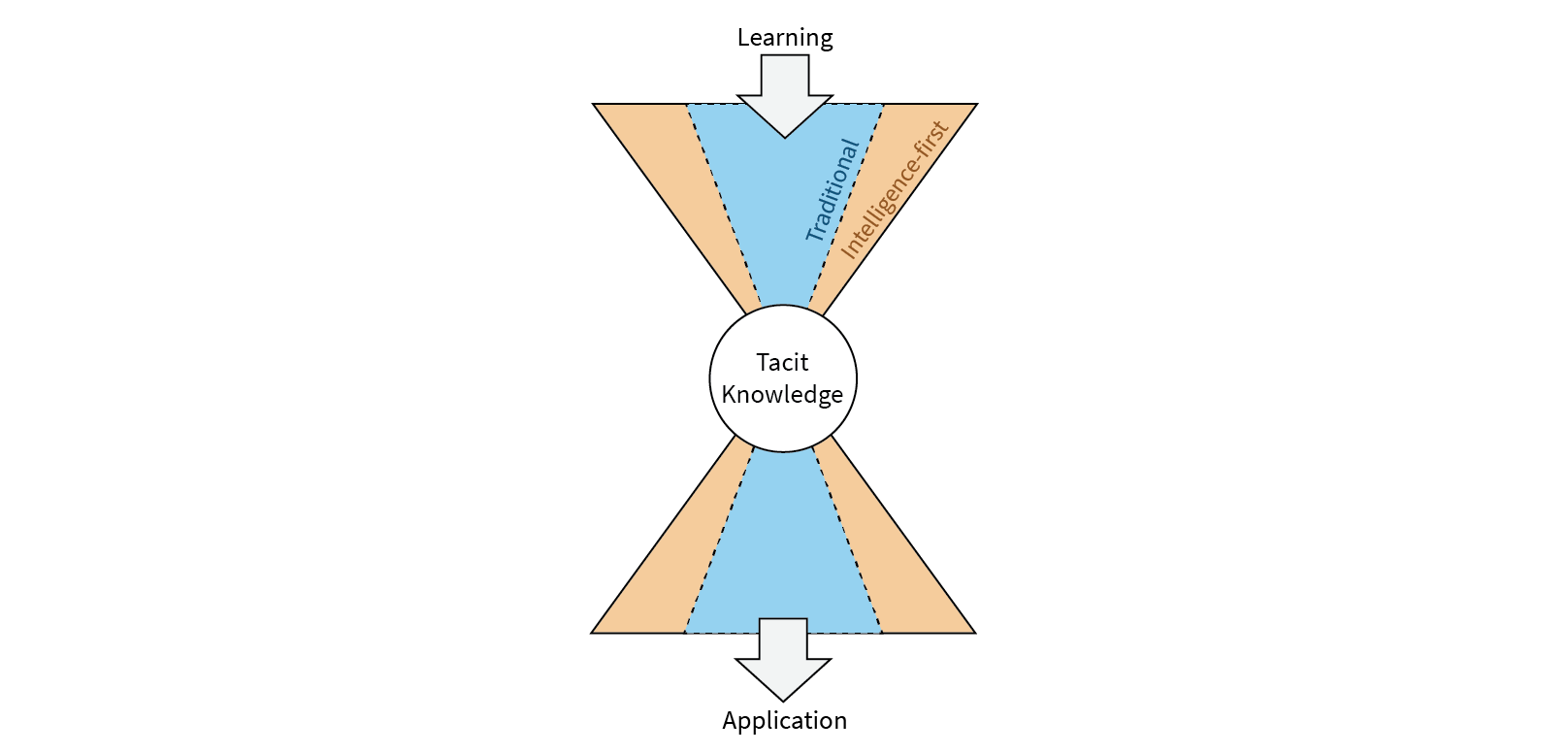
Another aspect of “perfection” is framing the problem in terms of data scarcity – I must have a complete dataset before I can start a predictive maintenance program. We have found that this just isn’t true. Too often seeking more data is an excuse to delay the uncertain aspects of the work – getting more data is comparatively easy to do and involves a well-defined process. Falkonry’s instead takes an intelligence-first approach. The idea behind this is simple – data collection is not the goal, solving problems is. That goal can be achieved by working on real-time data. Working in this “intelligence-first” way also circumvents two of the biggest issues in dealing with historical data:
- That it is hard to understand what really happened in the past. In our 8 years of experience, we have seen that reliability record keeping is an area that most organizations have difficulty with.
- That subject matter experts are reluctant to revisit old problems because they need to be focused on solving today’s problems. By working on issues that are happening now, it is much easier to get the subject matter expert input required to make good models and decisions based on those models.
Unfortunately, traditional data-science based approaches are difficult to use with intelligence-first. Data scientists are amazingly skilled at what they do, but typically they don’t have domain expertise in the area where the models are being applied. This makes them a bit of a 5th wheel that can slow down the process of discovering and interpreting problems. This is why we have built the Falkonry time series AI suite of products to be usable by the operations teams directly. That speeds up the process by making learning cycles shorter, ultimately leading to results which can scale across the entire plant.
Q: What is a good way to get started with using software to improve a reliability program?
Nikunj:
There are three basic ways to get started:
- Specialized sensor applications
- Customized prediction software
- Software-defined reliability approach
In a specialized sensor application, organizations implement sensors or instrumented equipment packages built to find and report on particular failure modes on certain models of that vendor’s products. This approach works for a limited set of issues on a limited set of assets for equipment performance issues but doesn’t take into account process issues where the equipment is used. To scale using this approach, you will need vendor specific solutions for all of your different equipment which covers all your different issues – this will get very expensive, very fast and may not even be possible for equipment which was deployed years ago despite having decades of productive life remaining.
The second approach is to use customized prediction software. This approach brings in data scientists to consult with SMEs and to model specific problems, which are then implemented into production software. As we have already discussed, this is not a scalable solution. It can be slow to implement and, when based on historical data, doesn’t engage the front line operations teams in their day-to-day work.
The last option is to use software that takes a general approach to reliability from any and all sources of operational data, and can be applied to a wide range of assets and problems making it easier to train and manage people. This is possible by directly engaging the operations teams instead of data scientists. We believe that Falkonry Clue and Falkonry Workbench fit into this role by hiding the complexity inherent in AI from the end users, enabling them to use it themselves and learn effectively.
This is the core of the Falkonry Time Series AI Platform – providing the operations teams an easy-to-use AI product that they can directly interface with in order to start providing actionable intelligence in a matter of weeks instead of years. This is a cornerstone of the intelligence-first approach we have been talking about.
If you are interested in learning more about the Falkonry Time Series AI Platform, click here. Or you can schedule a demo and we can work together on solving the problems you are facing.