Deep dive into Falkonry’s unique tech capabilities with CTO Dan Kearns

Key takeaways:
- The most obvious problems are often the easiest to approach, however, the most value remains locked in the long tail which Falkonry technology is aiming to address
- Deep learning and GPU acceleration hold immense potential, which is why the Falkonry product feature pipeline in these areas is growing incredibly fast
- Technology at Falkonry is always designed with two questions in mind: can it scale to large systems? And can it be productized?
Machines and processes today generate large quantities of time series data – so much so that it is the fastest growing type of data in the world at the moment. Keeping up with this data deluge is difficult not just for humans but even for analytics systems. AI-based technology is becoming increasingly important in addressing this problem and making sense of this data. In this interview, we sit down with Dan Kearns, CTO, Falkonry to understand cutting-edge breakthroughs in this space and how Falkonry is at the forefront of developing products that are able to scale rapidly.

Q: While time series AI is now starting to be acknowledged as the next megatrend for industry 4.0, why has it been such a tough nut to crack?
Dan: First, we should talk about why we call it a “mega-trend.” It is a megatrend primarily because of data volume. The data is there, it is huge, and production rates continue to accelerate. The economics of producing temporal observations have shifted by several orders of magnitude to the point where some very basic telemetry and reporting opportunities justify the implementation costs all by themselves.
Fairly early in the evolution of Falkonry, we realized just how unprepared the industry is to deal with even today’s data volumes. We thought there had been enough investment that the whole “IoT platform” issue was solved and we could focus on analysis methods alone, but we realized there is more work to be done. The architectures are wrong, the cost structures are wrong, the various theories on best practices around data stewardship really haven’t worked out well for many early adopters, and it’s just more work than it should be. So a big part of our investment focus over the last two years has been addressing the most important parts of that problem in a sustainable way and we now have a very solid, modern underlying platform that addresses data management with techniques suited to scaling meaningful analysis of that data.
The second factor that makes it a megatrend is a shared hypothesis that the observational data being collected harbors critical insights into various processes and the ability to harvest those insights will be crucial to remain relevant. So failure isn’t an option. Any organization that wants to have a say in its own future is facing the challenge of how to best deploy resources to harness this data and make it useful.
We believe that time series data analysis resembles other recent technology advances in that it has a very long tail of applications. We’ve seen that as new technologies emerge, the highest value problems are often the easiest to approach, at least from a management perspective, because it is obvious that focused solutions developed by experts are justifiable. Those are interesting and informative use cases, and we’ve certainly worked on our share of them, but what we are most passionate about at Falkonry is really figuring out how to address that long tail. We know that software and automation hold the key to solving long-tail problems, and that motivates us to really think deeply about the nature of the analytical challenges of time series and propose product-centric solutions that can scale organizationally.
As an industry, we are getting a little better at moving and storing large volumes of data, and we at Falkonry are definitely on the leading edge of some of those trends including columnar storage, vectorized calculations, and edge processing. But the data volumes we’re anticipating are so immense that the current state of the art falls over once we get to analysis and a different approach is going to be needed even before we get to the strategic issues.
Time series data has all of the challenges that other AI disciplines have, but usually in a more severe way. These include figuring out whether we are asking the right questions and then whether we are correctly interpreting the answers we get from our AI methods.
One of these challenges I would call a lack of vocabulary. For example, it’s fairly common for a time series-centric research paper to start with some phrase like “DNNs have been able to match or exceed human performance in vision problems, but…” One thing that is usually left out of the next sentence is that human performance on time series tasks isn’t even a thing. In this space, we’re really asking AI to do things humans have not been able to do well or sometimes at all. Describing temporal data in a way that would be useful for supervision purposes is very much a “dancing about architecture” kind of problem. Even some of the central concepts like “shape,” “trend,” or “anomaly” don’t have agreed-upon definitions.
Another challenge is that the continuous nature of time is often ignored. For example, almost all papers on classification assume the discrete segmentation problem has been solved already. That is pretty much never the case with the kind of use cases we handle. Events are considered to “happen” rather than evolving or emerging. Also, it’s generally not a valid assumption that the sampling rates used for observation are well matched to the behaviors we want to characterize.
Presentation is another challenge. Time series data often are viewed through a “domain” lens, where we intentionally bias the analysis. For example, we might present the frequency or quefrency domains as peers to the “normal” time domain, or we might animate, zoom, pan, or otherwise modulate the data to help direct attention to a-priori features where we expect contrast to be present. We might present the data aurally instead of visually, or use a spiraling time axis; there are just so many different ways to approach it. This makes teaching users a visual vocabulary and helping them interpret the charts important parts of the solution.
Q: Is there truth to the notion that computer vision AI problems are best suited for solving on GPUs while time series data is best crunched on CPUs?
Dan: There is… a little bit anyway. For one thing, time series AI and digital signal processing haven’t clearly evolved into two separate areas, and maybe there will never be a bright line separating the two. DSP has been around for a very long time and it has a deep set of supporting tools and methods, mature and ubiquitous hardware support, and a large ecosystem. Another factor here is that temporal deep learning architectures that necessitate GPU support are still evolving; there’s not the kind of consensus you might see in vision or NLP where the core architectures are pretty well accepted. All of this means there isn’t an obvious starting point for a general-purpose feature learning strategy and, as a result, you’ll see ensemble models of DSP-friendly features are still competitive in the various survey papers. In some ways, I’d say the initial bar for time series analysis is higher than it was for images and NLP. Even analog methods are still competitive here – we’re coming up on 100 years since you could identify an object using radar and an oscilloscope and, at least for me, it’s fun to grab some popcorn and google “tubes vs digital.”
The other benefit that CPU-oriented or DSP-oriented approaches have is scale-out. There’s just a longer history of commoditization, miniaturization, and other things you need. In other domains, you see very large models where bringing the data to the model is feasible. As a result, most of the GPU industry attention has really been on scale-up. With time series you can’t ignore the edge, you have to have some kind of strategy and a balance between the model complexity and the operational costs. One thing we’ve been working on is how to make large numbers of small models feasible. These small models can be bundled together to take advantage of heavier resources like GPUs, or unbundled and moved around to smaller and smaller edge devices, and they can take advantage of the GPU industry investments in video processing at the edge. It’s not all about the model architecture either. One thing we’ve learned is that the data flow infrastructure really has to be co-optimized with the machine learning infrastructure.
All that said though, we are really excited about the potential of both deep learning and GPU acceleration and are committed to and heavily investing in both areas. The results we’ve seen so far have been very promising, and the product feature pipeline from this work is growing incredibly fast.
Q: What are your thoughts on IT/OT convergence factoring into the evolving role of AI?
Dan: It’s unavoidable and essential. In the software industry, people often reference “Conway’s law” which basically says that system design mirrors organizational structure. The converse implication is that if you desire a certain system structure, you have to design your organization intentionally. Both IT and OT have “technology” covered in their names, so let’s be literal and assume that OT can make things work and IT cannot, and that IT can manage information well but OT cannot. What we’re aiming for with AI is to leverage information to make things work better, so we can’t involve only one of those functions. That means we have to have some kind of organizational tweak if we want a “system” that can support our goals.
This isn’t the worst lens to look through either. There are some obvious implications, such as funding for these projects comes from IT, and probably centrally because we’re trying to learn general skills and find technologies that will be applicable across our organization. But to get there we have to have specific successes and those have to come from OT, so we still need time and commitment from OT.
One thing we’ve found works really well as organizations get started is to introduce an internal concierge role, where someone is specifically tasked with learning how to translate between the information that AI models can highlight effectively, and the information that the operational professionals can consume easily. We’ve seen success with SME or domain experts taking on this role, and also when people with data science or ML backgrounds take on the role. The critical parts are the dedicated focus, commitment to communication, and intentional exploration of how to best extract business value from this new information source.
Q: What is the Falkonry approach to discovering unknown unknowns?
Dan: Unknown unknowns is a really fun concept. In most of our use cases, customers have an idea that some adverse behaviors are recurring and we work on the hypothesis that those recurrences should be predictable if there was just a way to detect the predictive pattern. That’s a regular unknown – we just have to figure out what that predictive pattern is.
One of the key aspects of the system we’ve built for these regular unknowns is that it deals gracefully with all kinds of data and label problems. We call it semi-supervised learning in recognition of the fact that ground truth in these kinds of use cases is really shaky, and a usable system needs to treat supervisory input as hints rather than traditional labels.
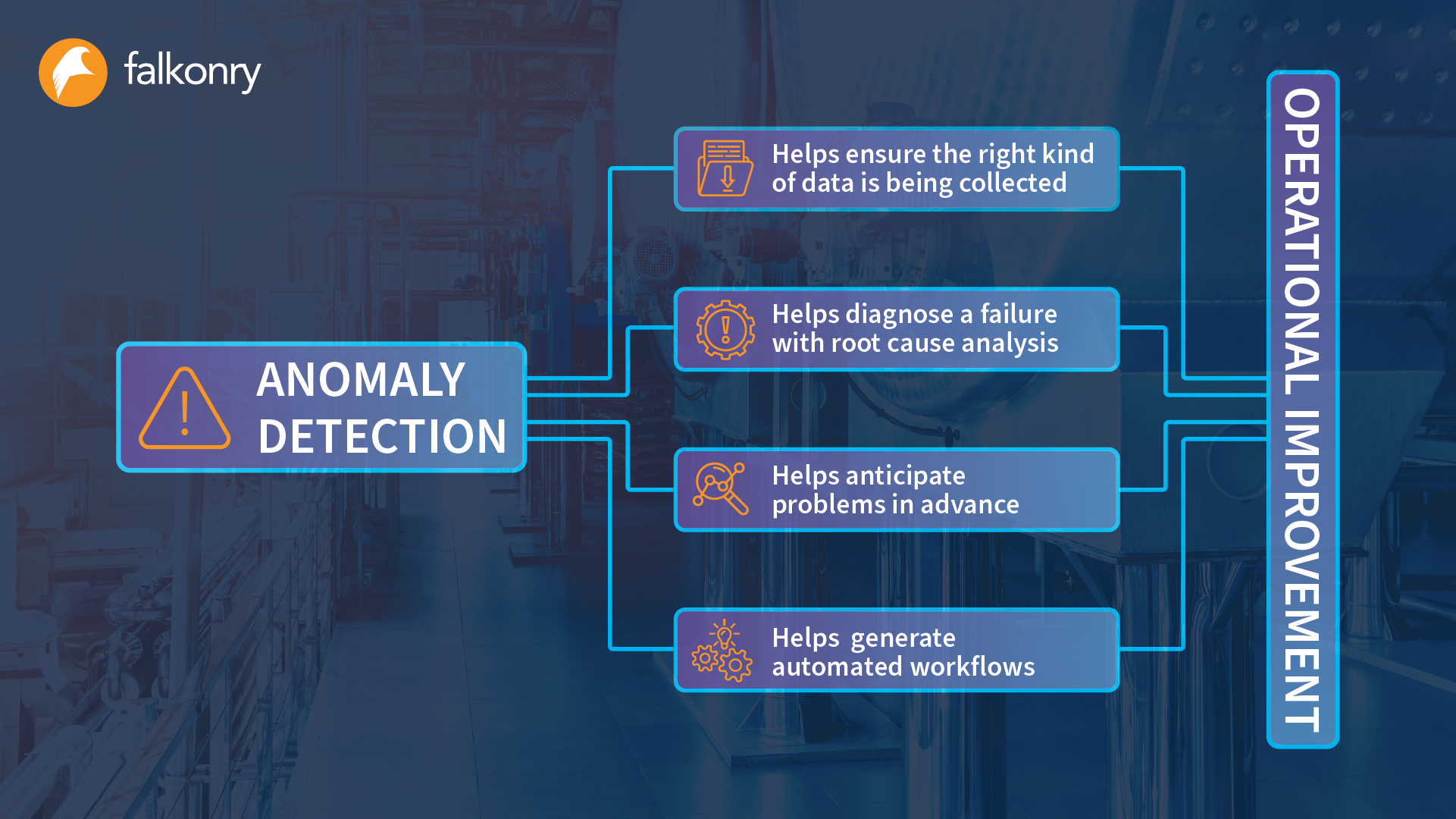
Unknown unknowns, on the other hand, are behaviors that have just never been seen before, and so the most difficult challenge is to efficiently detect and understand that kind of pattern. Anecdotally, this kind of behavior accounts for more than 30% of unplanned downtime in our customer base, and good tools for dealing with it are not yet available. For the past year, we’ve been developing a fully automated system to help identify and characterize these kinds of behaviors, and the first set of features showcasing our advanced anomaly detection capability is now part of Falkonry’s time series intelligence. 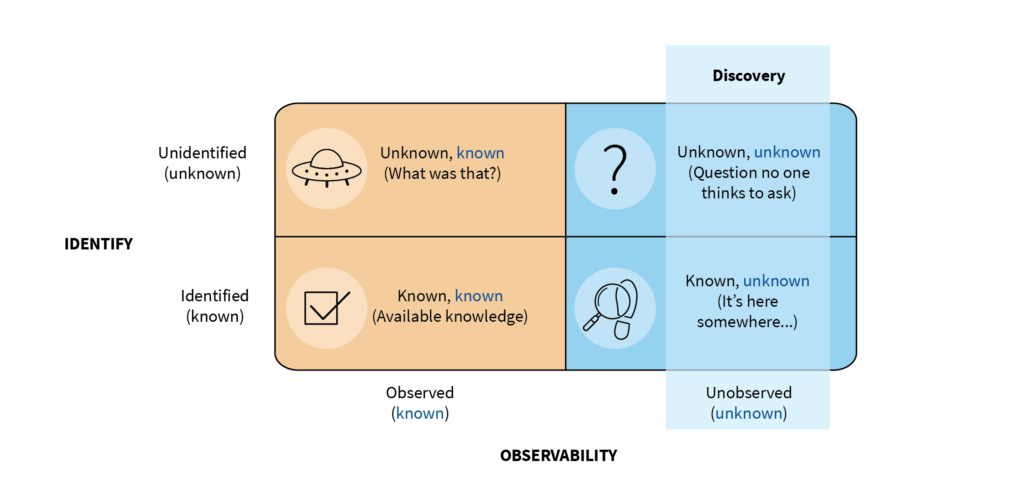
One important step in this process was to define, at least for our own purposes, the term “anomaly,” because it is really hard to make progress on the algorithms until you have a clear definition of what you want. Where we ended up is kind of an information-centric definition; anomaly for us is the degree to which our AI cannot learn and predict the behavior of a signal or a group of signals. This makes anomaly a continuous measure rather than a specific event, and it enables us to make a fully-automatic system to produce that measurement. The autonomous part is critical to this capability because obviously, we can’t know specifically what to look for if nobody has ever seen it before.
The second really important step here is a set of complementary tools and visualizations to help communicate the nature of anomalous behavior. If we can’t do that, then we’re really no better than the hot-take guys on sports shows wildly guessing why your favorite athlete is going to be a disappointment, and the operations professionals just won’t engage with the AI at all. This takes us back to the vocabulary problem we talked about at the beginning – how do we explain that there’s a new clicky-whirry-scratchy kind of thing happening with some piece of equipment? We believe we’ve figured out a way. Stay tuned for further updates.
Q: Can you give us a sneak peek into exciting developments within Falkonry R&D?
Dan: Oh man, there’s so much cool stuff I don’t know where to start. One of the things we’re excited about is the set of workflow capabilities we’re adding to the product. We have a lot of customers suffering from alarm overload at the lower levels of the traditional control pyramid. For several reasons, those systems, including the SCADA and HMI components, aren’t the place where you want to make a lot of changes. There’s a group of features we call “Agents” that will help in such situations by allowing rapid evolution and no-code automation where system events, including events the AI is producing, can be connected to responses. Those responses could be control-related activities, but more often they are useful to help with collecting and summarizing all the information that’s needed to help characterize a behavior, and to orchestrate human collaboration around whatever issues might be developing. Currently, there is a huge amount of inefficiency in just collecting the relevant data needed to really understand system behaviors, so this is going to make a big difference.
Another exciting area is a group of AI features leveraging our new contextualization capabilities. We’ve already released an unusually flexible signal catalog that allows hundreds of thousands of signals to be organized in many different ways simultaneously, and managed as they evolve over time without much effort. The new AI builds on this to enable Falkonry to be the extra eyeballs that can monitor an entire plant and report back in a way that resembles the feedback you see in movie spaceships – think “there’s a hull breach in sector 1 and we’ve been boarded” but there’s no specific sensor for either of those concepts, and that event has never happened before – we’re inferring it from correlated pattern changes in pressure, temperature, location, etc.
After that, now that we have built the data streaming platform we always wanted, there are some neat opportunities to extend our capabilities into other kinds of data that will make us relevant to more industries – for example, geospatial and cybersecurity. There we’ve had the good fortune to be working with some motivated partners to help us understand how our technology applies and we’ve been, I think, almost a poster child for the benefits of these newer public-private sector collaboration programs like the SBIR, where our commercial experience is helping us rapidly productize new technology for public-sector use, and our public-sector experience is helping us drive leading-edge work into the industrial space.
Q: What factors can lead to successful outcomes when deploying AI?
Dan: In my experience, I see two critical factors that maybe aren’t obvious to those just getting started. The first is to start with a human-in-the-loop mindset and not a controls mindset. Focus on the opportunities to reduce inefficiencies rather than trying to force a lights-out solution into existence for some specific occurrence.
The second critical factor is to think about scale and the long tail. Your advance team that gets the first project is likely to be successful based on just the superstar nature of that kind of team, but what would you need to repeat that effort, or to replicate it 100 or 10,000 times? There are enough opportunities hiding in the data for a wide and shallow strategy to pick off the easiest wins. Though executing a strategy like that has been a daunting challenge primarily due to a lack of supporting tools and processes.
That’s of course where we come in. What gets us up in the morning, and then keeps us up at night, is thinking of new ways to reduce the overall effort of making all this data useful. We always keep these two questions in the front of our minds: can it scale to large systems, and can it be productized? That focus, I think, is what has separated us as a company, and enabled us to achieve some pretty cool things.