Guide to IIoT Analytics
 Download Now
Download Now
Using data to control operations isn’t new. A host of techniques like SPC, TQM and Six-Sigma were developed over the decades and have proven very capable at improving operational capabilities across a range of metrics. These approaches have been very good at describing and diagnosing what happened in the event of simple problems. What is new is that modern computing technologies and machine learning (ML) approaches are changing the limits of what can be found within operational data in the event of complex problems. In particular, ML is well positioned to help with prediction i.e. the capability of answering the question: given this measurement, what is likely to happen? With these changes comes the necessarily messy search for how to actually organize and interact with these solutions. In this blog, we look a little more deeply at the ongoing transition from manual analytics to ML-driven approaches and provide some insight into how the search for the right predictive solution might be narrowed to yield a shorter path to useful results.
From a 50,000 feet level, conventional techniques share a common feature: they are human interpreted, statistical descriptions of the system or equipment. That is, they rely on humans to interpret summarized data to answer two questions about the system or equipment – what does it do (descriptive)? And why does it do that (diagnostic)? The descriptive aspect is perhaps best captured in the practice of Statistical Process Control (SPC), where behavior of the system is described in terms of averages and standard deviations for a set of measured variables (e.g. temperature, surface roughness, units per hour, etc). The diagnostic aspect is captured by practices such as Failure Mode and Effects Analysis (FMEA), where careful thought is put into understanding how the design of the system should reflect itself in the measurements of the system (e.g. when this valve leaks, pressure should drop here which results in the lower temp we see there). In both cases, understanding comes from human interpretation of the data.
Human cognition is limited when it comes to analyzing complex data and relationships. It is very difficult to “see” relationships across more than 2 or 3 variables. For example, while I can visualize the relationship between distance and time as a curve and intuit where something should be at some later time, I cannot visualize the hyper-volume which relates input power, coil frequency, coolant flow rate, chamber pressure and input flow rates of 4 gasses to intuit anything other than a few common operating conditions. It is also challenging to understand the impact of many coupled relationships on overall system behavior. For example, when a car hits a tree, it is not surprising if the tree falls over. However, it may be non-obvious that the cause of a high current alarm in an etcher is due to the particular cascade of feedback control compensations that the system made in response to a gas valve getting stuck open. Experiments also show that it can be hard to spot a difference that we aren’t looking for. Not every production line runs into problems where these kinds of complexity are the limiting factors but, as time has passed and more organizations have made an effort to become data driven, there are fewer and fewer low-hanging fruit, i.e. the problems which can be solved by understanding simple relationships between a few variables. This is why machine learning has become such a hot topic – ML naturally deals with high dimensionality, complex correlations and spotting novel behaviors. However, ML is still early in its application to many sorts of industrial problems and, as such, comes with its own set of challenges.
Machine learning runs on algorithms and data. Selecting and tuning the algorithms and collecting and preparing the data are non-trivial tasks. Even with the proliferation of open source ML libraries, choosing the right one, setting up the training environment, optimizing the algorithm settings, deploying the resulting models and understanding when and how to update models all require specialized training and quite a bit of hands-on experience. Most organizations, especially smaller organizations, don’t have the resources to hire data scientists, much less the number of data scientists required to make typical approaches to successfully deploying ML. Data gathering and data preparation face similar obstacles. Storing, retrieving, formatting and contextualizing sensor, business and operations data typically requires a number of different systems. Often, these are owned by different organizations, making comprehensive utilization of the data very difficult. These challenges, among others outside the scope of this blog, have kept many organizations stuck between the promise of ML and the reality of today’s human intervention-driven approach.

Digital twins are a way around the challenges of implementing ML. While there are many ways to think about what a digital twin is, the important part can be taken from this definition:
“Digital twins are the electronic representations of the product (and processes) which make both the data and applications required to perform one’s tasks readily available at each point in the product life cycle.”
Put another way, a well designed digital twin helps solve the data and algorithm problems discussed above by:
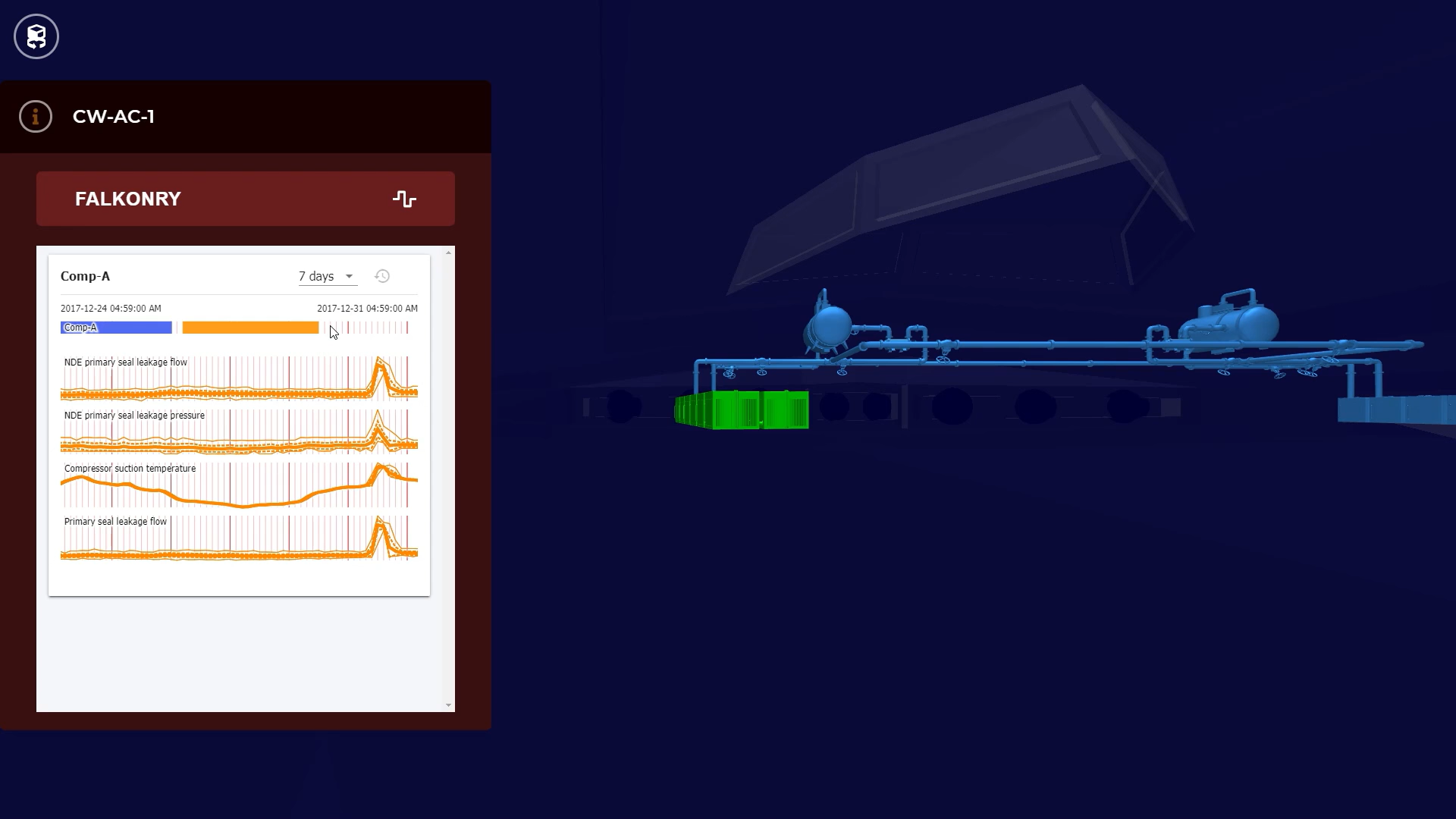
This is where Falkonry’s Predictive Digital Twins come in. We deploy discrete and composite digital twins that represent a machine or process and use machine learning to not only describe and diagnose behaviors, but also detect and predict conditions which negatively affect production.
Through over 8 years of experience working with customers in 12 industries across more than 400 use cases, we have developed a system which makes it easy for operations teams to apply machine learning without needing a data science team. Our time series AI platform is also built to make it easy to connect live or historical data sources. Finally, we have developed approaches which work, both with and without large volumes of high-quality historical ground truth data. By putting the data and analytic capabilities you need in one place, we can help you take that next step on your digital journey. Contact us to learn more