4 Myths of Maintenance Data

Key takeaways:
- Unproven assumptions about maintenance data lead to repeated disappointments and excessive risk to Smart Manufacturing
- The need of the hour is to overcome the limitations that these failed assumptions impose
- A possible remedy is software that narrows the effort to prepare data and in specific instances helps you to evasive action
Many in manufacturing assume that there is a relationship between their maintenance data and their machine data. Therefore, they believe that maintenance or failure events record the same information as machine data. This article is about four myths of maintenance logs and machine data that betray this belief: 1) Maintenance logs contain specific events, 2) People can correctly record maintenance events, 3) Machine data accurately records failures, and 4) Old data can be used to learn future behavior.

Inspired by success stories from the World Economic Forum, McKinsey & Company, Plattform Industrie 4.0 and CESMII many large ($1B to $10B) companies we worked with assumed that they could predict their maintenance to increase plant productivity. The assumption is the basis for their expectation that maintenance can be predicted from machine data and maintenance logs. However, most companies do not have any evidence that their traditional maintenance logs correspond to their machine data!
Myth #1. Maintenance logs contain specific events
To understand what I mean, consider an analogy of “conventional labels.” In the image below, if you know Catherine is in the following picture, what does that tell you? You would not know which person is Catherine or where in the picture is that face located. At other times, the face may be off focus, occluded, in poor light, or worse mislabeled altogether.

Courtesy: AndroidCentral
Just replace pictures with SCADA data, people with maintenance events, and you will get where I am going with this analogy. In our experience working with various manufacturers and producers, we have seen that manufacturers only have conventional labels of maintenance events and they don’t help to create any predictive models. In fact, there are very few or no recurring events, limited understanding of causes and effects, and no specific records of normal operation. Conventional maintenance records are logged for business purposes such as allocating costs to different cost centers or tracking inventory. However, we find that conventional maintenance records don’t correspond to degradation or line stoppage in their precise time, location, or cause.
Conventional labels just aren’t specific enough to predict anything useful. This is also the data preparation problem manufacturers face in adopting ML or AI. While data preparation is difficult but feasible for manufacturing quality problems, it is wholly unrealistic for machine condition, especially for manufacturers who run a whole assembly of different types of machines in different configurations to make different products.
Myth #2. People can correctly record maintenance events
In manufacturing, it is just not possible to outsource the labeling process because so much domain knowledge is needed to correctly label. But neither does anyone in the organization have the means to create digital labels. So how are we to move past this wall to bring industrial transformation? Some help is needed.
In the photo album analogy, the AI Cloud puts boxes around people’s faces and asks a user to name as many distinct faces as they want to. These inputs are digital labels and they are immediately used to connect birthdates and anniversaries and social identity of people to their pictures across the photo album. I hope you see why digital labels are essential to industrial transformation.
If the photo album knew the smallest box below contained Catherine’s face, you would actually have one example of Catherine’s picture even though that picture is partly covered by sunglasses. This could now be used to learn the meaning of the name Catherine.
 Courtesy: AndroidCentral
Courtesy: AndroidCentral
These days the photo album software people use is an AI Cloud. This Photo AI Cloud on its own knows (in a self-supervised learning process) how to put bounding boxes around people’s faces and is able to match these faces in different photos and backgrounds even if it doesn’t know their name yet. Such an AI Cloud doesn’t need any setup, it doesn’t need data scientists to operate, and provides not only the storage of photos and keeps a thumbnail on your phone but also brings up memorable events from time to time and offers you a picture you can share with your friend on their birthday. You can’t possibly do such fun things by labeling every face and captioning every picture. For such an AI Cloud, you would gladly pay monthly by the Gigabyte.
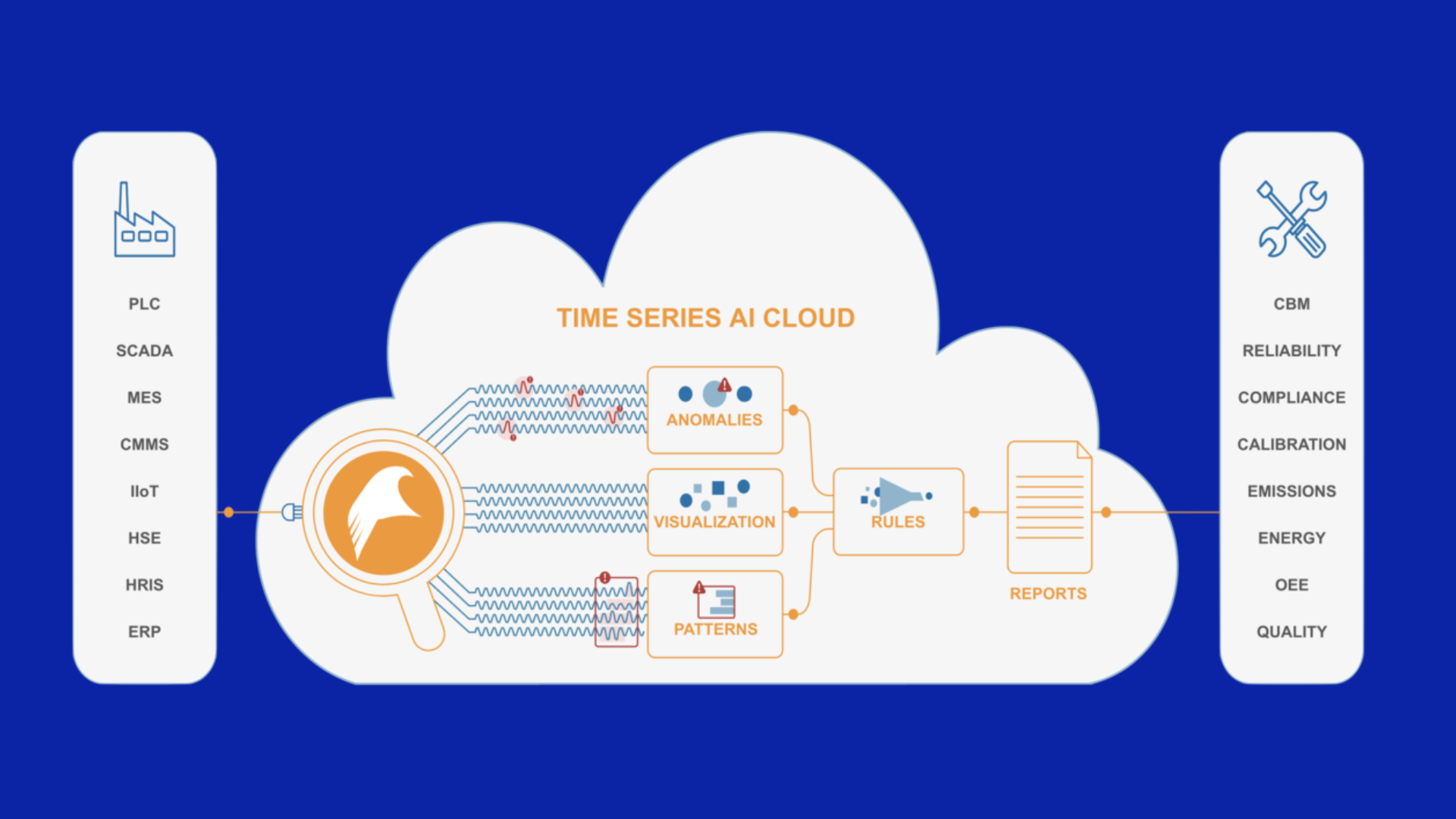
Automated time series anomaly detection is able to efficiently and in real-time find all the behaviors from machine data alone (self-supervised learning) that exceeds people’s knowledge.
Therefore, the first order of business with Industrial Transformation programs should be to apply a Time Series AI Cloud to prompt plant users to name as few behaviors as they want to, in other words to isolate periods of time and groups of signals that are anomalies and ask for a label to describe what was going on in that anomaly. We have seen through our years of experience working with leading steel producers all over the world that this is the closest they can come to producing digital labels. Even if they can’t label every box, just knowledge of the box is itself useful in anticipating trouble and taking evasive action. In fact, given the high level of reliability challenges in many plants, this is an effective and scalable approach, just like our photo album AI Cloud.
Myth #3. Machine data accurately records failures
While I have explained a way to leapfrog data quality issues in maintenance data, we have to realize that the same cannot be said about machine data. Machine data can still contain gaps in its ability to sense machine behavior either because it is not recording data as fast as necessary (Nyquist rate of sampling) or because it is completely missing the modality – e.g., only measuring current flowing into the pump but not the pressure in the hydraulic system attached to the pump.
This insufficiency is not even known by most people because they rarely even get to review events and find root cause in data. With an AI Cloud, it constantly and spontaneously locates unusual behaviors and, because failures are unusual, it puts boxes around the time and in the area where the failure event happens. This is how a lot of manufacturers develop confidence in their ability to avoid such failures through AI. This is also how they assess the adequacy of their machine data at helping them in industrial transformation. Most of the time, this data comes from PLC and SCADA systems but occasionally people also have secondary sensing such as from IIOT Sensors. Before spending hundreds of thousands on dollars and a few years deploying new specialized sensors, we should know what is the value instrumentation built into control systems can provide.
Myth #4. Old data can be used to learn future behavior
Ever seen someone reconstructing a family tree just from centuries of photographs passed down through the generations? It is painful because of photo degradation, changing faces of people, undeveloped film, conventional labeling challenges and inscrutable handwriting.
Holding on to years of data doesn’t really help you learn about the events you want to evade. If you really want to evade events, you have to begin finding novel behaviors from recent data and learn how to act on them. If you are creating digital labels, then you are at least chipping away at the deficit of understanding your data and acting based on your data. Over time, you can review more of your old data to the extent you can correctly locate it. At the same time, AI Cloud will get even better, and it will organize and link together more than machine data with more engineering and operational data.
Summary
The software that moves you in the direction of digital labels and data comprehension creates tremendous value for your organization by narrowing the effort to prepare data and in specific instances helping you to evasive action. But the latter is not a substitute for the former. One way to find a needle in the haystack is to shuffle the hay in the barn to find the needle and the other is remove everything that is hay out of the barn so that you can separate everything that remains and if there is a needle, it will be obvious and visible.
Effectively, the AI Cloud helps curate and prepare the data by finding the relation between events and the data sources that show the effects of the event as well as by accurately recording the events.
As Nitin Joglekar and others say in their MIT Management Review article, when you are able to measure the inputs and outputs of your industrial transformation project in the form of creation of new capabilities and options, delivery speed, or the risk of not implementing the system, and others, you are already setting the right foundation for success.
I have illustrated how fatally flawed is the premise that is possible to have your cake and eat it too if you have machine data. You can literally save millions of dollars of data prep and IT integration/data science effort, and at the same time make millions of dollars of more production during the years you saved in the process.