Continuous Improvement of an Operational AI Deployment

Key Takeaways
- Continuous improvement of operational AI systems is needed because information is imperfect and incomplete.
- There are a wide range of AI improvement triggers ranging from normal equipment variation to changes in product mix.
- Iterative improvement to Operational AI is difficult because traditional systems separate learning from usage. Falkonry’s approach to predictive production operations overcomes this limitation.
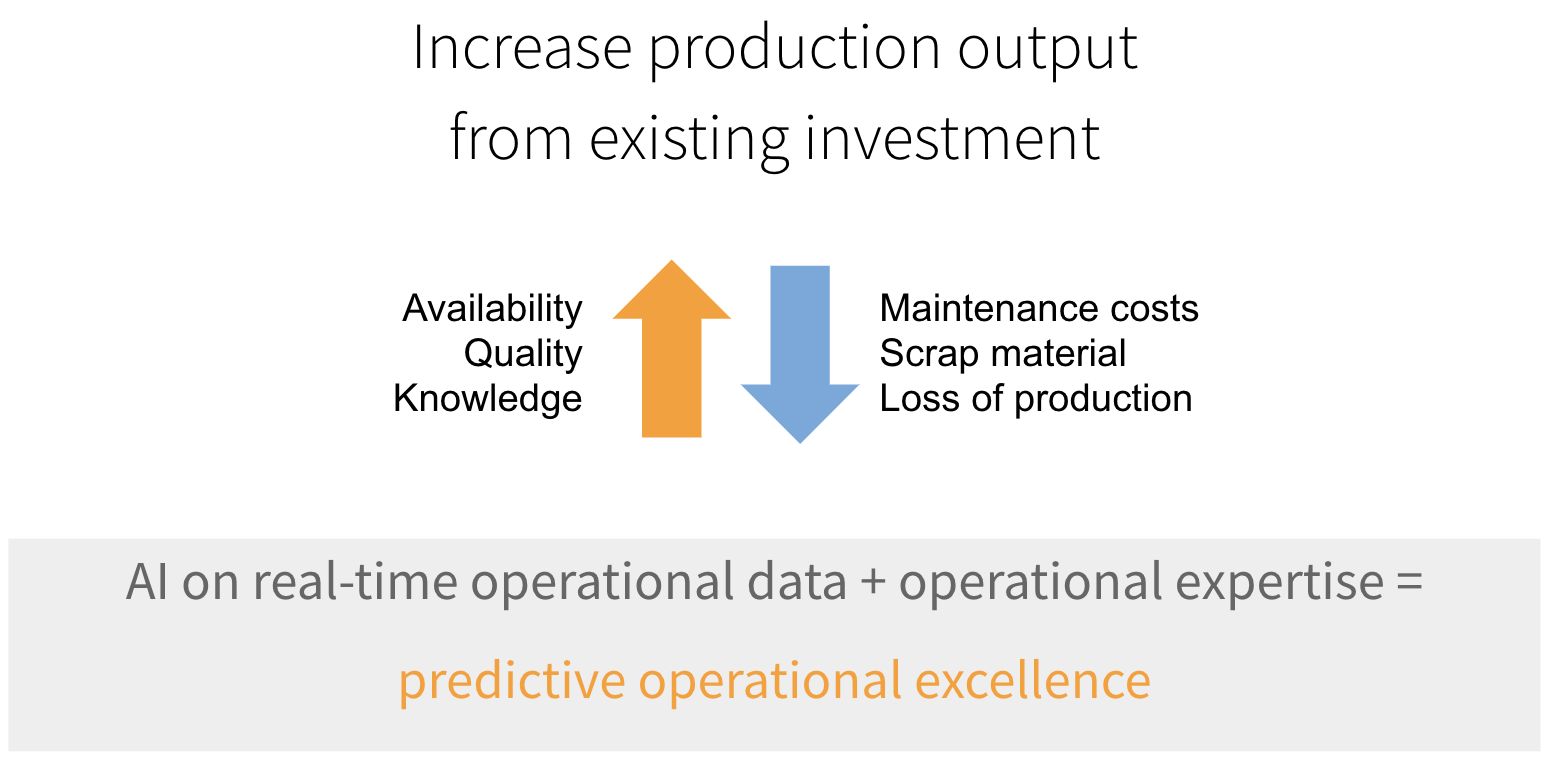
Using machine learning to achieve predictive operational excellence is not a build-it-one-time-and-it’s-done prospect. Production is a dynamic process. The systems which enable it and the products being built change over time. Continuous improvement (sometimes called “model maintenance”), capturing these changes, is at least half the challenge of an operational AI solution.
At a high level, the challenge boils down to one thing: Being able to describe everything that the system might do so that it is possible to recognize any behavior when it occurs again. However, it is very rare that one has understanding of, much less recorded, historical examples of, the full range of system behaviors. For example, a quality prediction system was found to produce warnings for one specific production asset at specific times of the day regardless of actual product quality. After much investigation and some luck, it was found that a loud speaker above the affected asset broadcast regular announcements coinciding with the quality alerts. This interaction between the speaker and the specific asset’s operational data output had not been observed before and, therefore, could not have been accounted for ahead of time in any operational AI model.
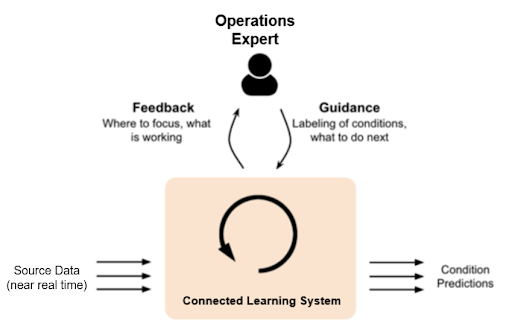
Lacking perfect information, we build and deploy with the limited knowledge we have. Then we improve the operational AI over time so that it can cope with the states we didn’t know about. To help clarify the breadth of what can trigger such improvements, here are some common situations.
- Normal variation over time
Learning periods can be short relative to the full operational cycle of the asset. This can result in normal behaviors being unrecognized by the operational AI system. For example: If I learned what weather in Tokyo was like based on observations taken in November through April, I would be very surprised at the anomalous behavior of June through August. To avoid such surprises in the future, I would improve the operational AI by adding examples of weather from the summer months.
- Sensor drift
Sensors aren’t perfect and the environments they are in can be harsh. This results in measurement variance even if the underlying conditions have not changed. For example: an optical temperature sensor might observe a reaction chamber through a quartz window. As the chamber ages in the course of a normal service cycle, that window can become dirty, affecting the temperature reading. Opening the chamber to clean the window every time it begins to get dirty has been deemed too expensive, making the variance unavoidable. The drift that this wear-induced change causes could affect prediction outcomes. Improving the operational AI in this case might mean adding examples with different levels of window occlusion covering a normal servicing cycle.
- Baseline shifts after servicing
System behavior can be sensitive to replacement parts and calibration of those parts. A routine part swap, as might occur during a service cycle, could change sensor readings, adversely affecting predictions but without affecting the product quality. For example: A vacuum pumping system might have three different operational modes depending on the specific brand of pump installed. If the operational AI system were trained using examples with only one pump type installed, it would produce anomalous results when a different pump type was installed. Improvement of the operational AI might mean adding examples of the pumping system running with the two other pump models installed.
- Changing process
Incoming material changes, improved knowledge of the system, increased throughput targets, all of these things can result in changes to the way equipment is normally operated. These changes can result in inaccurate predictions. Improvement of the operational AI, in this case, would require capturing examples of the system’s behavior with the new operating parameters and adding them to the learning set so that the new normal can be properly understood.
- Changing product mix
Some manufacturing lines produce a range of different products using the same equipment. Each product requires that the equipment run in a different manner. When the mix of products change, the predictions from the operational AI can become inaccurate. For example: A rolling mill processes steel sheets with two different hardnesses. If the operational AI learned when the harder steel was processed infrequently, its predictions may underestimate wear when the harder steel becomes the primary product being run. Improvement would mean learning with new examples of operational data which represent the new proportions of steel types.
Continuous improvement of Operational AI is a challenge not only because of the time consuming work of gathering new ground truth facts, collecting new operational data sets, learning the new behaviors and validating the prediction results, but also because the improvement process is separate from on-going usage. That is, updating the system takes extra effort by a special team. There are ML automation systems designed for data science teams to help manage this effort, but the scalability problem remains: adoption of predictive operations at scale succeeds when the operational teams can do the work themselves.
Predictive production operations (PPO) take a different approach to the challenge of iteratively improving operational AI. PPO uses adaptive learning where the validity of the predictions are confirmed at the same time that they are put to use by the operational expert. Value is extracted and operational AI is improved in the same step, using the same data. This is more effective than presenting a result to a data scientist who reviews it at some later time without context or the benefit of the operational experts’ knowledge.
There is no way to avoid surprises. Information is never complete and never perfect. However Falkonry’s approach to PPO, as embodied in Falkonry Clue, addresses this challenge cleanly and effectively. By taking an intelligence-first approach, Clue seamlessly connects alerts to actions. This enables you to pursue operational excellence with less effort spent on operational AI maintenance and to realize predictive value earlier than with alternatives.